ChatGPT連携サービス


 ChatGPT連携サービス
ChatGPT連携サービス
 生成AI
生成AI
 AI受託開発
AI受託開発
 対話型AI -Conversational AI-
対話型AI -Conversational AI-
 ボイスボット
ボイスボット
 バーチャルヒューマン
バーチャルヒューマン
 教師データ作成
教師データ作成
 ナレッジマネジメントツール
ナレッジマネジメントツール
 AI研究開発
AI研究開発
 通訳・翻訳
通訳・翻訳
 AI・自動受付システム
AI・自動受付システム
 声紋認証
声紋認証
 機密情報共有・管理
機密情報共有・管理
 契約書管理システム
契約書管理システム
 ワークステーション
ワークステーション
 FAQシステム
FAQシステム
 AIカメラ
AIカメラ
 生体認証
生体認証

 電子帳簿保存法の電子保存対応ソフト
電子帳簿保存法の電子保存対応ソフト
 インボイス制度対応システム
インボイス制度対応システム
 データセットの収集・購入
データセットの収集・購入
 コールセンター
コールセンター
 人事・総務向け
人事・総務向け
 インバウンド対策
インバウンド対策
 コンバージョンアップ
コンバージョンアップ
 KYT・危険予知で労働災害防止
KYT・危険予知で労働災害防止
 無料AI活用
無料AI活用
 顧客リスト自動生成
顧客リスト自動生成
 ロボットで自動化
ロボットで自動化
 LINE連携
LINE連携
 セキュリティー強化
セキュリティー強化
 テレワーク導入
テレワーク導入
 AI学習データ作成
AI学習データ作成
 配送ルート最適化
配送ルート最適化
 非接触AI
非接触AI
 受付をAIで自動化、効率化
受付をAIで自動化、効率化
 AIリテラシーの向上サービス
AIリテラシーの向上サービス
 日本語の手書き文字対応AI-OCR
日本語の手書き文字対応AI-OCR
 Windows作業の自動化RPAツール
Windows作業の自動化RPAツール
 リスク分析AIで与信管理
リスク分析AIで与信管理
 紙帳票仕分けAI-OCRサービス
紙帳票仕分けAI-OCRサービス
 サプライチェーン
サプライチェーン
 自治体向けAI
AIコンサルティング
自治体向けAI
AIコンサルティング


最終更新日:2024/02/21

近年はさまざまな分野でAI・人工知能が活用され始めており、「AIだからこそ実現できるもの」も多くなってきました。そのため、AIによる新たな可能性の実現に向けて、機械学習モデルの構築にフォーカスする企業も多いでしょう。しかし、機械学習モデルの構築を行う上では、AI学習データが欠かせません。そのAI学習データによって機械学習モデルが構築されるため、「データがどのように動くのか」を理解していくことも大切になるわけです。
では、このAI学習データとは一体どのようなものなのでしょうか。今回は、機械学習モデルを構築するために必要なAI学習データについて詳しく解説していくとともに、機械学習向け画像データセットの作り方や、Web上のオープンソースのデータセットなどをご紹介していきます。ぜひ参考にしてみてください。
教師あり学習について詳しく知りたい方は以下の記事もご覧ください。
AIの基礎「教師あり学習」とは?種類や具体例を紹介

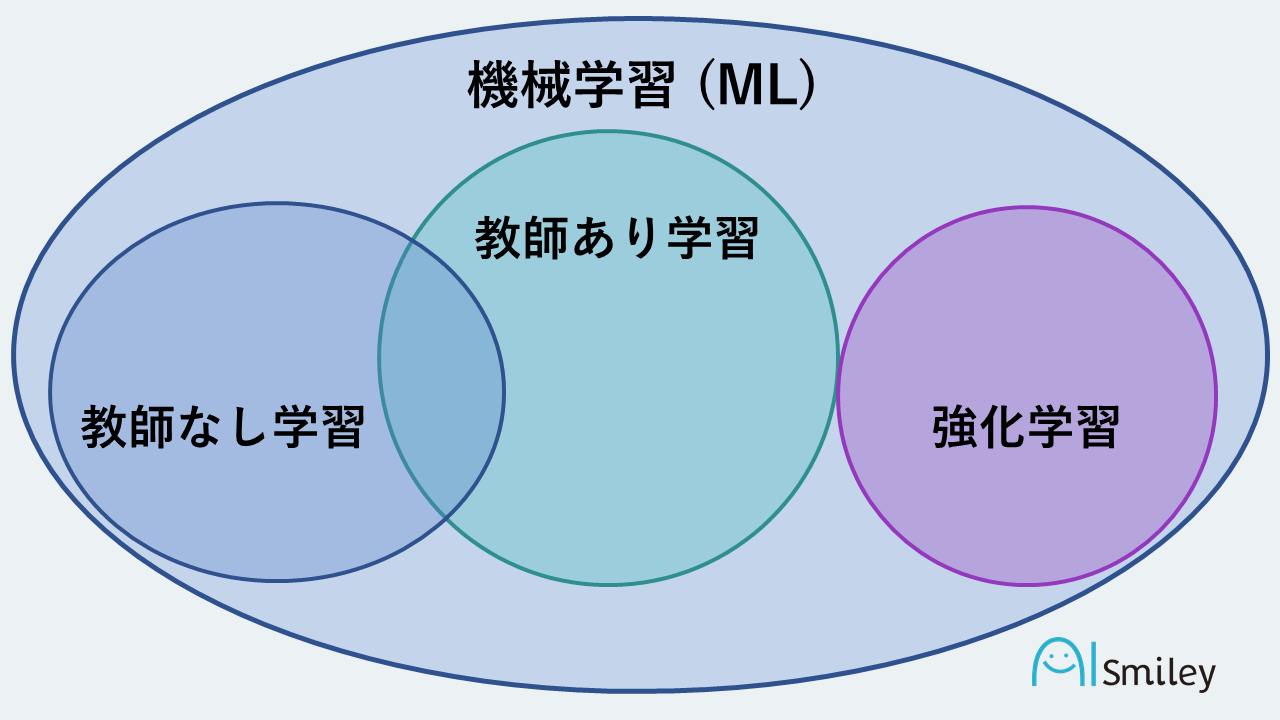
機械学習とは、機械が膨大な量のデータを学習することによって自らルールを学習し、そのルールに則った予測や判断を実現する技術のことです。学習方法には、膨大な量のデータを学習して特徴を把握していく「教師あり学習」と、さまざまな次元でデータ分類などを行う「教師なし学習」、そして自ら試行錯誤して正解を求めていく「強化学習」の3種類が存在します。
AIにおける機械学習の位置付けとしては、「AIの要素技術の1つ」と表現することができるでしょう。そんな機械学習には、教師あり学習、教師なし学習、強化学習といった種類が存在します。
教師あり学習では、正解となるデータをあらかじめ読み込んだ上で、正解に紐づく結果を提示することが可能です。教師なし学習では、正解となるデータが存在しないため、入力されたデータを利用して正解を導き出していきます。一見、教師なし学習のほうが難しいように思えるかもしれませんが、適切な方法で学習を行えば、教師なし学習でも精度を高めていくことが可能です。
そして、強化学習では、データを活用せずに、設定された結果を評価するという形で最善の方法を探っていきます。バスケットボールのゲームを例にすると、パスが成功するたびに1ポイント、得点が入ると50ポイントといったアルゴリズムを搭載することで、自身で最適の方法を導いていくわけです。最近大きな注目を集めている将棋AIには、この強化学習が活用されています。これらを踏まえた上で、具体的に機械学習でできることとしては、「画像の判別」や「将来予測」といったものが挙げられるでしょう。
Facebookなどのサービスに搭載されている人間の顔を判別する機能には、機械学習が活用されています。これは、自分自身の顔が写っている写真を自動で判別し、「○○さんと一緒にいます」と表示させることができるというものです。この「写真の判別」は、機械学習によってユーザーの顔を認識しているからこそ実現できるのです。
これまでに蓄積されたデータを機械学習することによって、将来がどのようになるのか予測することも可能です。このアルゴリズム自体は複数存在しますが、適切なものを洗濯すればより精度の高い予測を行うことが可能になります。場合によっては、スポーツの試合結果や株価なども予測できるようになるかもしれません。
機械学習モデルとは、データ解析を行う方法のひとつであり、私たち人間が行っている「経験を通して学ぶ」ということをコンピューターで実現できます。機械学習モデルには「入力→モデル→出力」というプロセスが存在します。これは、コンピューターが受け取った入力データをもとにインサイトを抽出し、モデルが具体的な評価(判定)を行った上で出力するというものです。
たとえば、人間が会話している音声をコンピューターが文字起こしする場合、入力データである音声をモデルが受け取り、音声認識によって「統計的・確率的」なパターンに照らし合わせ、解析していきます。そして、その解析結果を出力することで、初めて音声が文字に起こされるわけです。近年では、SiriやAlexaといった音声アシスタントも生まれていますので、機械学習モデルはまさに「機械学習の中心的な役割を担う頭脳的存在」といえるでしょう。
もし、機械学習モデルが存在しなければ、コンピューターは単純な計算しか行うことができなくなります。つまり、データに合った柔軟な結果を示すことができなくなるということです。
また、機械学習では、蓄積されたデータから関係性を見出し、インサイトを得て情報処理していくため、その蓄積データが多くなるにつれて出力の精度も高めていくことが可能です。常に最新のデータが求められる現代において、機械学習モデルは必要不可欠な存在といえるでしょう。
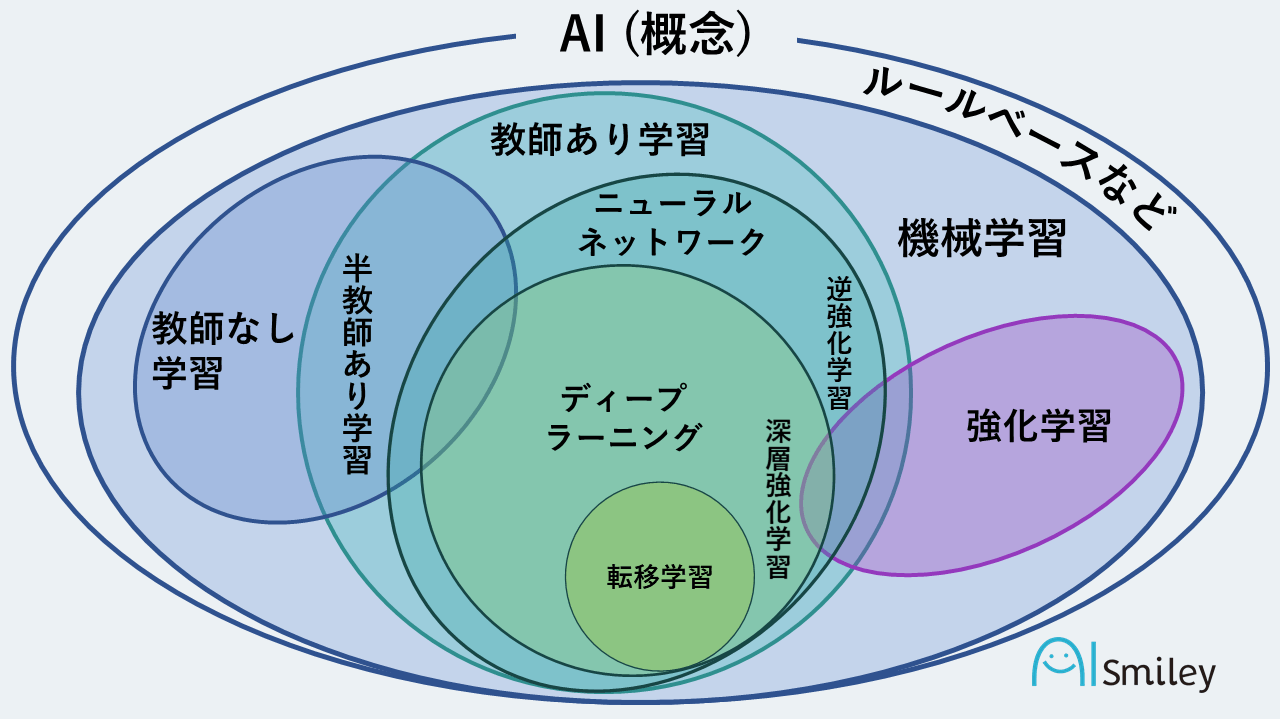
ディープラーニングとは、膨大な量のデータを学習し、共通点を自動で抽出していくことによって、状況に応じた柔軟な判断を下すことが可能になる「機械学習技術の内の1つ」です。従来の機械学習と異なる点としては、より高精度な分析が可能な点が挙げられます。
ディープラーニングの位置付けは、機械学習の一部である「教師あり学習」の一部となります。最近では、ディープラーニングについて学べる書籍やディープラーニング関連の資格・検定なども増えてきており、より専門的な知識を学びやすい環境が整いつつある状況です。
また、東京大学大学院工学系研究科 特任准教授の松尾豊氏が理事を努める「日本ディープラーニング協会」によって産業促進も促されており、ディープラーニングの普及スピードは加速し始めています。

アノテーションとは、音声や画像、テキストといったさまざまな形態のデータに対し、関連する情報(メタデータ)を注釈として付け加えていく作業のことを指します。「さまざまな形態のデータにタグ付けを行う作業」という意味の言葉であると考えれば分かりやすいでしょう。また、最近ではYouTubeの動画上で表示される、クリックも可能なアノテーションがYouTubeに投稿されている多くの動画で見かけるようになりましたので、一度は目にしている方も多いでしょう。一方、AI業界におけるアノテーションは、「機械学習のモデルを作成する上で必要となる教師データ(正解データ、ラベル)の作成作業」を指します。
さまざまな形態のデータに対してタグ付けを行い、そのタグ付けされたデータを取り込むことによって、AIはそれぞれのデータのパターンを認識することができるようになり、アルゴリズムを学習できるのです。逆に、正確なタグ付けを行えていないデータを取り込んでも、AIは正しく学習することができません。そのため、機械学習アルゴリズムを学習させるためには、タグ付けしたデータが必要不可欠といえるわけです。
そんなアノテーションですが、種類はひとつだけではありません。最近では、自然言語処理を活用したゲノム解析のアノテーションなども話題になっています。さまざまな種類のアノテーションが存在しますので、代表的なものを見ていきましょう。
意味的アノテーションとは、人の名前や商品名、企業名など、テキスト内のさまざまな単語に対して意味付けを行うアノテーションのことです。主に、検索エンジンにおける関連性の改善や、チャットボットの学習などに用いられています。
画像・映像アノテーションは、機械学習による画像認識・映像処理の精度を高めるためのアノテーションです。機密情報の漏洩防止や商品リストの分類、自動車の自動運転など、さまざまな分野で活用されています。当然こういった機械学習モデルには画像・映像の内容を理解するための力が求められるため、画像認識や映像処理を機械学習アルゴリズムに正しく学習させるためにも、正確にタグ付けされたデータを大量に用意することが重要になるわけです。
文節チャンキングでは、名詞や動詞、形容詞といった品詞にタグ付けを行います。品詞がひとつ変わるだけで文章の意味合いが大きく変化することも少なくないため、文章の意味を正しく理解する必要がある「チャットボットの開発」などにおいては文節チャンキングが欠かせません。
テキストやコンテンツの分類も「アノテーション」に該当します。テキストやコンテンツの分類というのは、具体的には、あらかじめ定義したカテゴリを、フリーテキストで書かれた文書に割り当てていくという作業です。これにより、文書内の文や段落を、トピックごとにダグ付することなどが可能になります。
ニュースサイトで、「芸能」「スポーツ」「政治」といったカテゴリごとに表示されているのを目にしたことがある方も多いのではないでしょうか。こういったニュース記事のカテゴリ分けは、まさにこのアノテーションによって実現されているものなのです。
エンティティアノテーションとは、AIが正しく文章を認識できるように、非構造化文章にタグを付ける作業のことを指します。「エンティティ」は、データの構築を行う際に、「人」「物」「地名」「事象」「サービス」といった対象物をカテゴリごとに分ける作業のことです。このエンティティに基づいて非構造化文章にタグ付けをすることで、AIが文章を正しく認識することができるようになるのです。
ただ、このエンティティアノテーションにもさまざまな種類が存在しており、多くのソリューションでは複数のシステムが組み込まれています。そのため、データサイエンティストが要棟に応じた方法でデータを操作することが可能です。
チャットボットを構築する場合、ユーザーから寄せられた質問の意図を適切に認識できるようにするアルゴリズムが必要可決です。たとえば、旅行サイトのチャットボットに対して以下のような問い合わせが寄せられたとします。
・キャンセル料を支払うので、予約をキャンセルしたいです。
・キャンセルする場合、キャンセル料は発生しますか?
・無断でキャンセルした場合のキャンセル料はいくらですか?
上記の文章にはすべて「キャンセル料」という言葉が含まれています。しかし、それぞれの文章の「意味」は大きく異なるものであることがお分かりいただけるでしょう。そのため、チャットボットがこれらの「意味」を的確に理解できるようにしておかなければ、「キャンセル料がいくらなのか知りたい」という問い合わせに対して「キャンセルを申請している」という誤った認識をしてしまう可能性があるのです。
このようなミスを防ぐためにも、意図抽出によって語句や文というレベルでのタグ付けが必要になります。文章を適切に理解する上で、この意味抽出は極めて重要であることがお分かりいただけるでしょう。
AIに学習させたいデータに対し、意味付けを行っていくアノテーションは、AI開発において非常に重要な役割を担っています。なぜなら、このアノテーション次第でAIの精度が決まるといっても過言ではないからです。言い換えれば、適切なアノテーションを行うことができれば、精度の高いAIを構築できる可能性が高まると考えて良いでしょう。
たとえば、高い精度が求められる自動運転技術の場合、より多くの教師データを用意することによってAIの精度も高めやすくなります。ドライブレコーダーの映像や画像など、AI学習のために準備する作業は大きな負担となりますが、この作業こそがAIの精度を高める上で欠かせないものになるのです。
また、アノテーションをしっかりと行ったAIを開発できれば、AI運用後の業務効率を大幅に高めることも可能になります。業務効率化だけでなく人件費削減にも繋げられるため、アノテーションによってAIの精度を高めることには大きなメリットがあるといえるでしょう。

実際に機械学習向け画像データセットを作る場合、どのような方法で作成していけば良いのでしょうか。ここからは、機械学習向け画像データセットの作り方について、順序ごとに詳しくご紹介していきます。
画像データセットを作成する前の作業として、機械学習プロジェクトの課題を明確化させることが大切になります。「どのようなモデルを構築するのか?」「構築したモデルによってどのような課題が解決されるのか?」といった点を明確化させましょう。
もちろん、企業がAI導入する場合以外のケースも考えられますので、個人が趣味の範囲で行う場合には、「機械学習に触れてみること」を課題とする形で問題ありません。ただし、企業がAI導入する場合には、「AIを導入すること」自体を課題とするべきではないでしょう。AIの導入によって解決したい問題こそが本質的な課題といえるからです。そのため、特定の業務を自動化することや、株価や製品需要などの予測を行うことなど、課題を明確化すると良いでしょう。
課題を明確化できたら、早速機械学習プロジェクトに適した画像の収集作業に入ります。AIは基本的に教師データとの「質」と「量」が大きな影響を与えるため、教師データの質と量を高めていくことで機械学習モデルの精度も向上していくと考えましょう。ただ、オーバーフィッティングを避けることも大切ですので、必要に応じて少しずつ教師データの量を増やしていくという考え方も重要になります。
社内のデータベースに蓄積された既存のデータだけでは不十分な場合には、画像データセットを作成してくれるサービスを利用するのもひとつの手段です。
必要な量の画像データを収集し、画像データの整理が完了したら、機械学習モデルのヒントとなるアノテーションを付与していきます。たとえば、画像認識の場合、画像がインプットデータとなるため、アノテーションは「その画像に何が含まれているのか」を示すものになるわけです。
同じ画像を利用する場合でも、目的次第ではアノテーションの仕方が大きく異なります。多く用いられる方法としては、画像や映像フレームに描かれた架空の箱であるバウンディングボックスが挙げられるでしょう。アノテーションプラットフォームを提供する企業の中には、人間の顔パーツをより正確にアノテーションできる円型のバウンディングボックス機能を有している企業も存在します。そういった機能を有効活用するのもひとつの手段といえるでしょう。
なお、画像データを利用する際に気になる部分として著作権が挙げられますが、AI開発を目的とする場合には、一定条件のもとで著作権者の許諾なく著作物を利用することが可能です。また、2019年1月1日の法改正より、著作権法30条の4によって「AIにおける著作物の取り扱い」は柔軟化されました。AIを生成するために準備されたデータセットを、第三者に向けて販売したり公開したりすることが適法となっています。

良質なAI学習データを活用することには、さまざまなメリットが存在します。特に大きなメリットとして挙げられるのは、以下の3点です。
それぞれのメリットについて、詳しく見ていきましょう。
教師あり学習において、AI学習データは予測や分析の精度に大きな影響を与えます。教師あり学習とは、正解となるデータをもとに、そのデータのパターンやルールを学習して、分析モデルとして出力する機械学習の手法です。そのため、正解となるデータを大量に学習させれば、予測や分析の精度を高めることも可能になるわけですが、その学習データの質が低いと、予測や分析の精度を落とす原因となってしまいます。高い精度の予測や分析を実現する上では、質の良いAI学習データが欠かせません。
近年は、ビッグデータ関連のサービスやAI関連の市場が活性化しています。それに伴い、アノテーションの需要も高まってきているのです。多くの企業がアノテーションに注目し、その需要に応えるサービスが増加していくことで、よりアノテーションの質も向上していくことが期待されます。質の良いAI学習データを利用できるメリットは数多く存在するため、今後もアノテーション需要の変化には注目すべきでしょう。
近年は、AI学習データを提供するサービスも多くなってきています。そのため、AI学習データがない企業は「外部から収集する」という手段を選択するのも効果的といえるでしょう。より質の高いAI学習データを収集できるかどうかは、AIによる予測・分析の精度にも大きな影響を与えるため、外部から収集するという選択肢は、企業によっては大きなメリットとなるでしょう。
近年は、さまざまなデータがオープンに公開されており、気軽に活用することができます。もちろん、オープンデータのみを活用して競合優位性のあるAIを構築するのは現実的ではありませんが、独自に収集したデータと組み合わせれば、独自のAIを構築していくことも可能です。
企業によっては、競合優位性のあるAIを構築する必要があるケースも考えられます。しかし、オープンデータだけでは競合優位性のあるオリジナリティ溢れたAIを構築することはできません。独自のAIを構築するためには、独自に収集したミクロのデータと組み合わせていくことが大切になります。そのため、オープンソースのみを活用していく場合、独自のAIを構築することが難しくなるというデメリットが生じるでしょう。
ここからは、Web上のオープンソースのデータセットをご紹介していきますので、ぜひ参考にしてみてください。
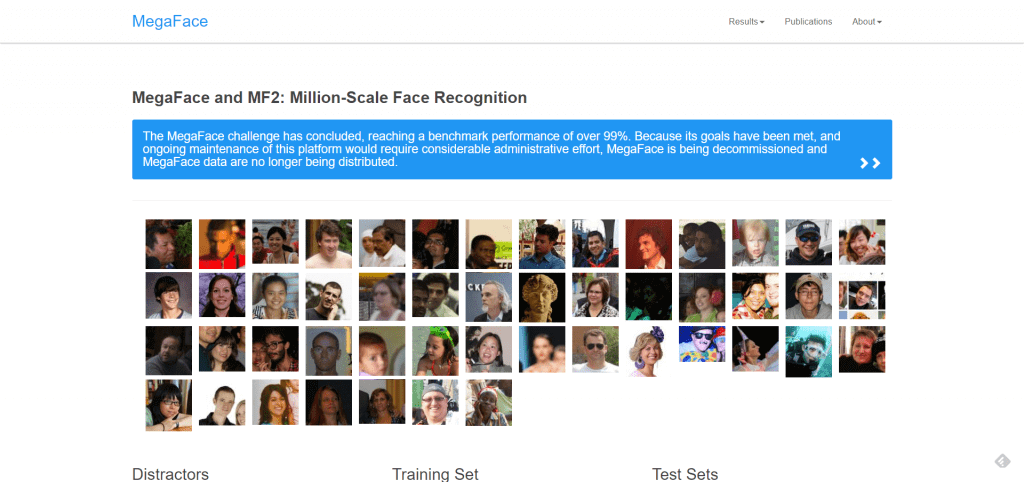
MegaFaceは、アメリカのワシントン大学で行われている顔認識アルゴリズムの公開競技で用いられている、ノイズデータを混ぜた顔認識と大規模なデータセットです。

Pascal VOC Datasetは、オブジェクトクラス認識用の標準化された画像データセットです。「データセット」「注釈にアクセスするためのツール」の2つがセットで提供されています。
Google Open Image V4は、Googleが公開しているデータセットです。約900万枚の画像データに対して、「画像レベルのラベル」「オブジェクトの境界ボックス」「オブジェクトのセグメンテーションマスク」「視覚的関係」がアノテーションされています。

ImageNetには、1,400万枚以上のデータセットがあります。文字列検索を行うと、検索単語に合ったクラスが出てくるため、より簡単にデータを取得することが可能です。
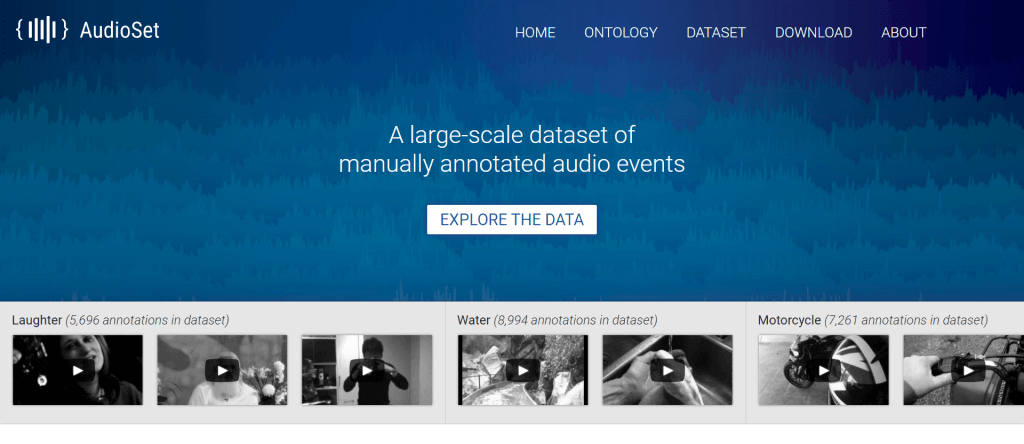
AudioSetは、Googleが公開しているオープンソース・データセットです。10秒程度の音に、人間の声、動物の鳴き声、楽器といったラベルが付与されています。
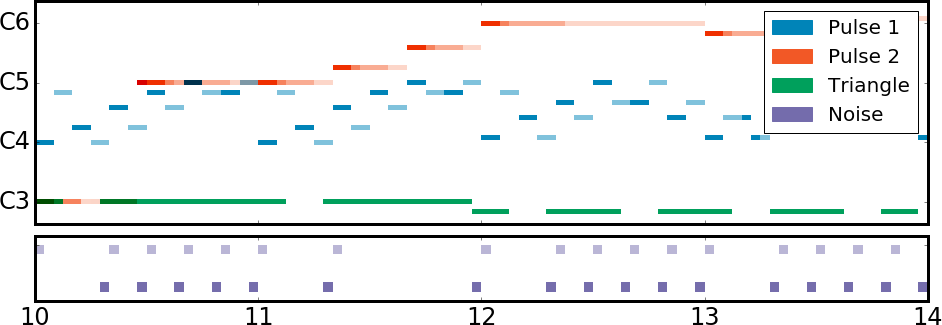
The NES Music Databaseは、スタンフォード大学のポストドクターが公開しているオープンソース・データセットです。自動音楽構成システムを構築する人向けに公開されています。397タイトル、計5278曲が含まれているのが大きな特徴です。
Mozilla Common Voice は、Mozillaが展開する「Common Voice」という音声データセット収集プロジェクトの中から、42,000貢献者、18言語、約1,400時間の音声データが公開されているオープンソース・データセットです。
Speech Commands Datasetは、Googleが公開しているオープンソース・データセットです。Tensorflow向けの音声認識を構築する人に利用されています。30種類の短い単語を発音した長さ 1 秒の データが65,000 個含まれています。
「自然言語処理のためのリソース」は、京都大学の黒橋・河原・村脇研究室が公開しているオープンソース・データセットです。自然言語処理用のツールやデータセットの情報がまとめられています。
「日本語対訳データ」では、機械翻訳システムの構築に利用できる対訳コーパスや、対訳辞書などが公開されています。
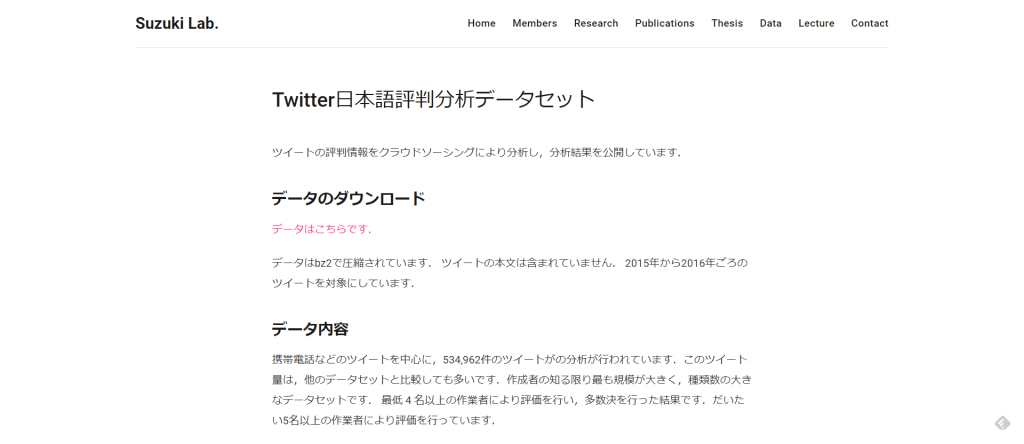
「Twitter日本語評判分析データセット」では、ツイートの評判情報をクラウドソーシングによって分析した結果が公開されています。
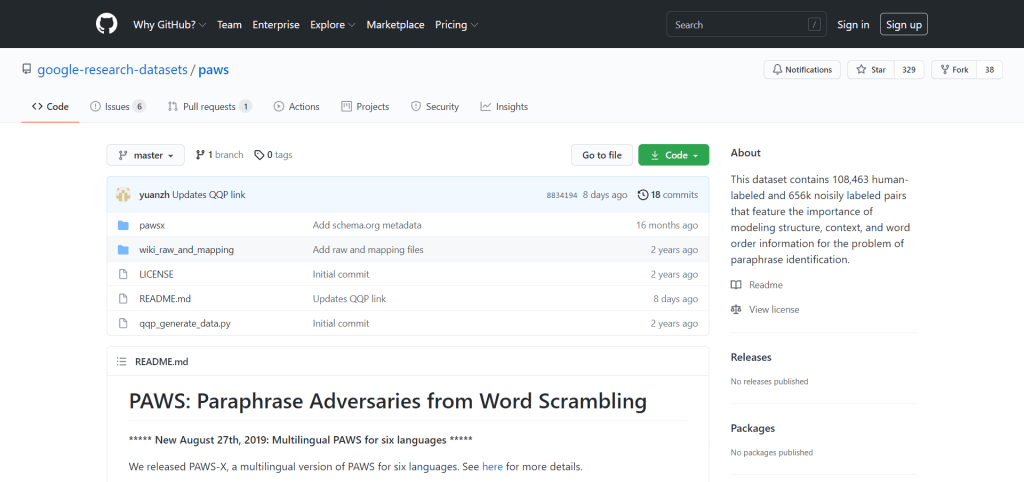
「PAWS」は、単語の順番や構文構造が異なると意味が変わってしまう言い換えを克服するためのデータセットです。
![]()
TASUKI は、SBイノベンチャー株式会社が提供しているアノテーションサービスです。AI開発に使用する教師データの収集・加工を行うことができます。画像、自然言語、音声等、様々なアノテーションに対応しているのが大きな特徴であり、ソフトバンクのAIエンジニアの豊富な開発経験をもとに、「さくっと頼めて、高品質な成果を生み出すアノテーション代行システム」が構築されています。
作業者の誤解作業をなくし、品質への安心感をとことん追求したアノテーション代行サービスとなっているため、「アノテーションを自社エンジニアで実施している」「外部依頼したけど品質に満足できなかった」という企業でも、コストを抑えながら問題を解消することが可能です。
![]()
harBestは、株式会社APTOが提供している「クラウド発注型」のAI学習データ作成サービスです。アノテーション作業はもちろんのこと、データ収集から依頼することもできます。
また、独自の品質自動評価機能を搭載しており、より高品質なデータを提供してもらえる点は大きな魅力といえるでしょう。
機械学習において、データ収集・作成は最も面倒で時間のかかる作業です。そのため、それらの作業を効率化もしくはアウトソースしたいとお考えの方も多いでしょう。harBestであれば、Webから発注するだけで、データ収集・作成作業を任せることが可能です。面倒で時間のかかるデータ作成から解放されるため、別の重要な作業に力を注ぐことができるでしょう。
![]()
「AIデータ作成支援」は、NEC VALWAY株式会社が提供しているサービスです。物体や人物などのテーマによって、依頼した画像データ等に対するアノテーション、タグ付けなどを実施します。NEC VALWAY株式会社では、各業種で用いるAIの認識精度向上のため、データ作成や正解付けの業務支援で500PJ以上の実績があります。その豊富な実績は大きな魅力のひとつといえるでしょう。

音声データ作成サービスは、株式会社翻訳センターが提供しているサービスです。「音声データ収録」「音声書き起こし」「アノテーション」「話者感情データ作成」といった音声認識エンジン用データ作成や、対話エンジン用データ作成に必要となるシナリオライティングなどを依頼することができます。
音声認識・チャットボット・ロボットなどのサービスが一般化していく中で、AIエンジンの精度向上はもはや必要不可欠なものになりました。株式会社翻訳センターでは、AIエンジン(音声認識・対話シナリオなど)向けに学習用データはもちろんのこと、各種データを作成するサービスが用意されているため、音声認識エンジン用データ作成や対話エンジン用データ作成を依頼したい企業にとって最適なサービスといえるでしょう。

アノテーション・ソリューションサービスは、株式会社ヒューマンサイエンスが提供しているサービスです。ヒューマンサイエンスでは年間4,800万以上のデータをアノテーションしており、生産性と正確性のパフォーマンスを独自のマネジメントシステムで管理しています。外注活用の仕組み作りからコンサルティングサポートしており、オンサイト、オフサイト、オフショアなど、要件に合わせた柔軟な体制構築が実現されています。
「自然言語分類」「物体検出」「意図抽出」「領域検出」「音声認識」「地図ルート検索機能」「OCR」「機械翻訳」といったさまざまなサービスが提供されており、様々な分野の翻訳、マニュアル制作で培った豊富なリソースとノウハウによって、様々な要望を最適なカタチで実現することが可能です。迅速・柔軟な対応や変更を求められる大手外資系IT企業との多数の取引から培ったノウハウを豊富に蓄積している点も、大きな魅力のひとつといえるでしょう。

株式会社Ristが提供する「Data-Centric AI powered by LandingLens」は、製造業の外観検査AIにおけるAIモデルの学習、現場へのデプロイ、運用時のフィードバックまでをトータルにサポートするクラウドサービス「LandingLens」の導入サポートおよび技術サポートサービスです。 LandingLensは、その優れた革新性と利便性から、数々のアワードを受賞しています。
アンドファン株式会社が提供している「AI学習用教師データ作成サービス」は、ミャンマーの優秀で若いスタッフにより、画像データや動画、ネット上の情報などから様々な機械学習用のデータを作成するアノテーションサービスです。
大量データの作成業務を得意としており、特にラボ型契約のBPOサービスにおいては管理体制やセキュリティ管理をお客様に合わせて構築・運用することができます。
![]()
東京反訳株式会社が提供している「AI学習用文字起こしサービス」は、文字起こしの専門会社による音声認識に特化したアノテーション付帯サービスです。文字起こし専門会社として15年以上積み上げたノウハウを基に、高品質な教師データが提供されます。

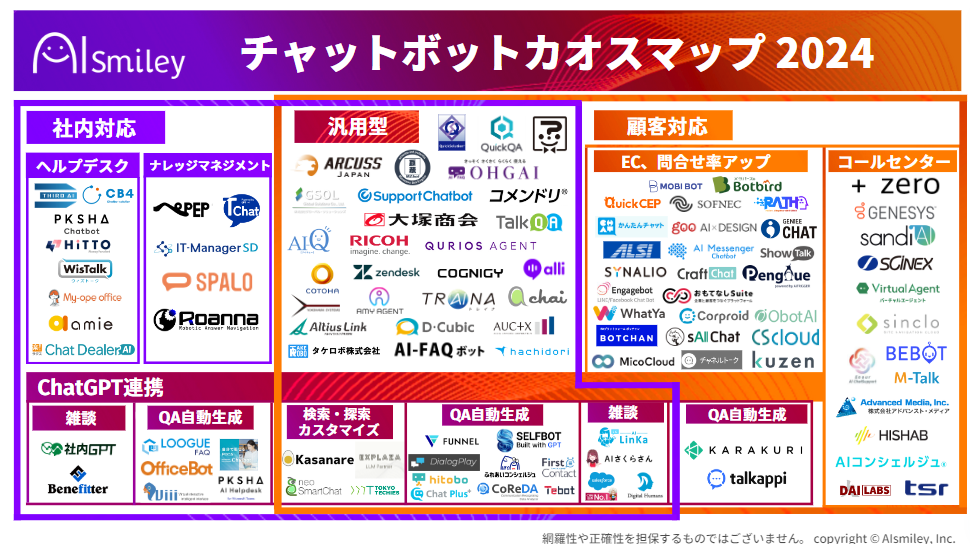
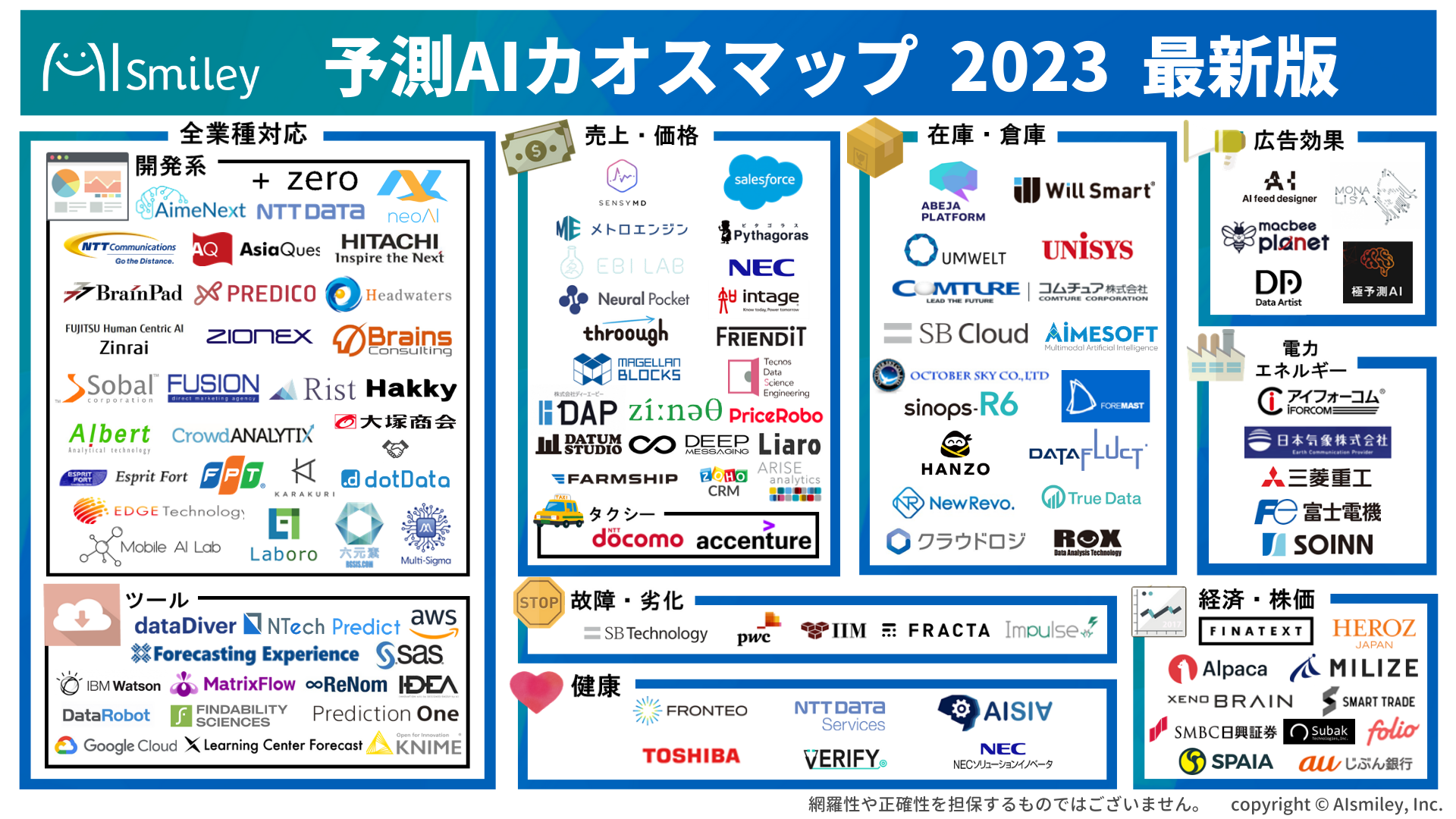
AIsmileyでは、アノテーションのサービスやツールをまとめた「教師データ作成カオスマップ」を公開しています。近年、アノテーション関連サービスを提供している企業も多くなってきています。人材を提供するサービスが一般的ですが、専用ツールを販売したり、その両方を提供したりする企業も多くなってきている印象です。
AIの活用が一般的になりつつある現代だからこそ、ぜひこの機会にアノテーション関連サービスにも目を向けてみてはいかがでしょうか。今回のカオスマップは、サービスやツールをマッピングしたもので、「アノテーションツールや委託先を探したい」という方に向けAIsmileyが独自の主眼で作成したものになります。是非本資料を手に取っていただき参考にしてみてください。
今回は、機械学習モデルを構築する上で必要となるAI学習データについて解説するとともに、質の良いAI学習データを活用するメリットや、オープンソース・データなどを詳しくご紹介しました。
近年は少子高齢化に伴う人手不足が深刻化していることもあり、多くの企業にとって「業務効率化」は重要なキーワードとなるでしょう。だからこそ、さまざまな業務の効率化・自動化を実現できるAI(人工知能)は、必要不可欠な存在となっていくことが予想されます。
より高い精度で予測・分析を行えるAIを構築するためには、アノテーションが欠かせません。だからこそ、今回ご紹介したオープンソース・データセットの活用と併せて、さまざまな企業が提供するアノテーションサービスの利用も検討してみてはいかがでしょうか。
最近では、アノテーションを行うアノテーターをアルバイト雇用することで、サービス品質やスピードの向上に繋げる企業も多くなってきています。そのため、よりスピーディーにAIを構築したい企業にとっても、アノテーションサービスの利用には大きなメリットがあるでしょう。
なお、AIsmileyでは、アノテーションのサービスやツールをまとめたカオスマップを公開しております。気になるAIアノテーションサービスの一括見積もりも可能ですので、ぜひお気軽にご利用ください。
機械学習について詳しく知りたい方は以下の記事もご覧ください。
機械学習とは何か?種類や仕組みをわかりやすく簡単に説明
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
学習方法には、膨大な量のデータを学習して特徴を把握していく「教師あり学習」と、さまざまな次元でデータ分類などを行う「教師なし学習」、そして自ら試行錯誤して正解を求めていく「強化学習」の3種類が存在します。
具体的に機械学習でできることとしては、「画像の判別」や「将来予測」などが可能になります。
ディープラーニングとは、膨大な量のデータを学習し、共通点を自動で抽出していくことによって、状況に応じた柔軟な判断を下すことが可能になる「機械学習技術の内の1つ」です。従来の機械学習と異なる点としては、より高精度な分析が可能な点が挙げられます。
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。







.png)




FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら