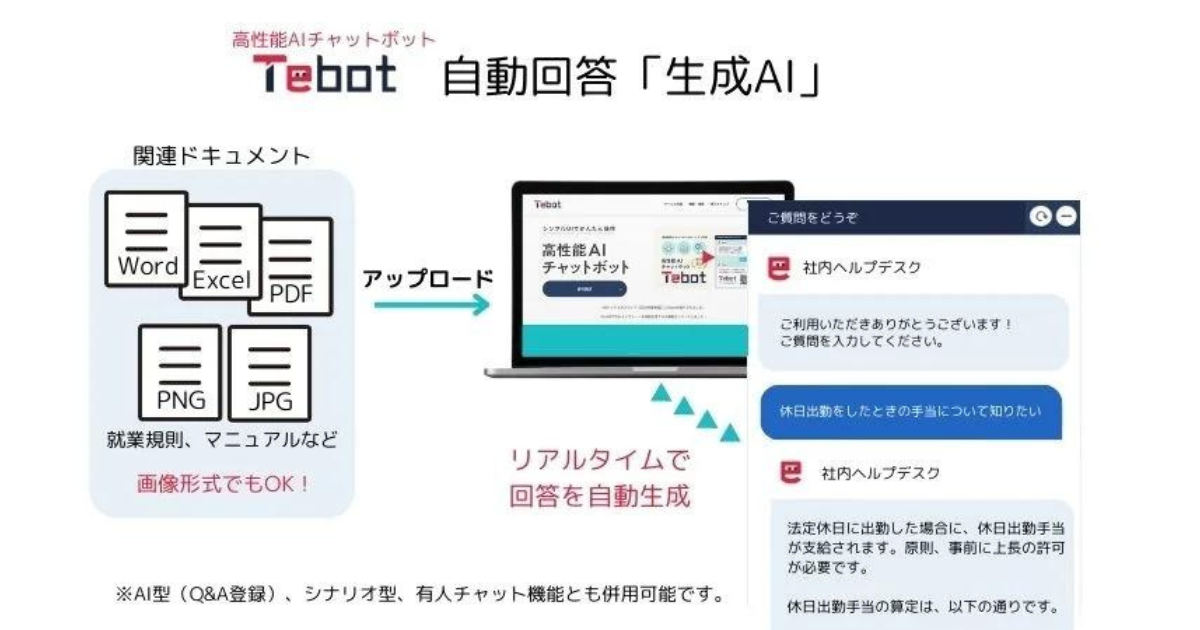
ChatGPT連携サービス


 ChatGPT連携サービス
ChatGPT連携サービス
 生成AI
生成AI
 AI受託開発
AI受託開発
 対話型AI -Conversational AI-
対話型AI -Conversational AI-
 ボイスボット
ボイスボット
 バーチャルヒューマン
バーチャルヒューマン
 教師データ作成
教師データ作成
 ナレッジマネジメントツール
ナレッジマネジメントツール
 AI研究開発
AI研究開発
 通訳・翻訳
通訳・翻訳
 AI・自動受付システム
AI・自動受付システム
 声紋認証
声紋認証
 機密情報共有・管理
機密情報共有・管理
 契約書管理システム
契約書管理システム
 ワークステーション
ワークステーション
 FAQシステム
FAQシステム
 AIカメラ
AIカメラ
 生体認証
生体認証

 電子帳簿保存法の電子保存対応ソフト
電子帳簿保存法の電子保存対応ソフト
 インボイス制度対応システム
インボイス制度対応システム
 データセットの収集・購入
データセットの収集・購入
 コールセンター
コールセンター
 人事・総務向け
人事・総務向け
 インバウンド対策
インバウンド対策
 コンバージョンアップ
コンバージョンアップ
 KYT・危険予知で労働災害防止
KYT・危険予知で労働災害防止
 無料AI活用
無料AI活用
 顧客リスト自動生成
顧客リスト自動生成
 ロボットで自動化
ロボットで自動化
 LINE連携
LINE連携
 セキュリティー強化
セキュリティー強化
 テレワーク導入
テレワーク導入
 AI学習データ作成
AI学習データ作成
 配送ルート最適化
配送ルート最適化
 非接触AI
非接触AI
 受付をAIで自動化、効率化
受付をAIで自動化、効率化
 AIリテラシーの向上サービス
AIリテラシーの向上サービス
 日本語の手書き文字対応AI-OCR
日本語の手書き文字対応AI-OCR
 Windows作業の自動化RPAツール
Windows作業の自動化RPAツール
 リスク分析AIで与信管理
リスク分析AIで与信管理
 紙帳票仕分けAI-OCRサービス
紙帳票仕分けAI-OCRサービス
 サプライチェーン
サプライチェーン
 自治体向けAI
AIコンサルティング
自治体向けAI
AIコンサルティング


最終更新日:2024/01/19
Appierのミン・スン氏が、新型コロナウイルス対策とビジネス推進に有用な、「シーケンシャル・データのモデリング」に関する考察と予測を発表しました。
このAIニュースのポイント
AIテクノロジー企業のAppierのチーフAIサイエンティスト、ミン・スン氏が、新型コロナウイルス対策とビジネス推進に有用な、「シーケンシャル・データのモデリング」に関する考察と予測を発表しました。
なお、シーケンシャル・データとは、連なったデータと定義し、並んでいる順番に処理することや、連続して立て続けに処理することを指します。
ミン・スン氏は、現在フェイクニュースの検出などで利用されている「シーケンシャル・データのモデリング」が、新型コロナウイルスの突然変異の予測、抗ウイルス薬の開発にも活用され始めていると説明しました。
新型コロナウイルス関連の研究論文は、世界中から毎日新しいものが発表されています。
日本では東京大学や理化学研究所のAIPセンターなどが発表しています。
AIがその膨大な量の研究論文を集約・分析することや、ソーシャルメディア上で新型コロナウイルスや感染症対策に関する「フェイクニュース」の検出を可能にしています。
「シーケンシャル・データのモデリング」は、生物医学領域の系列データ予測にも活用されています。
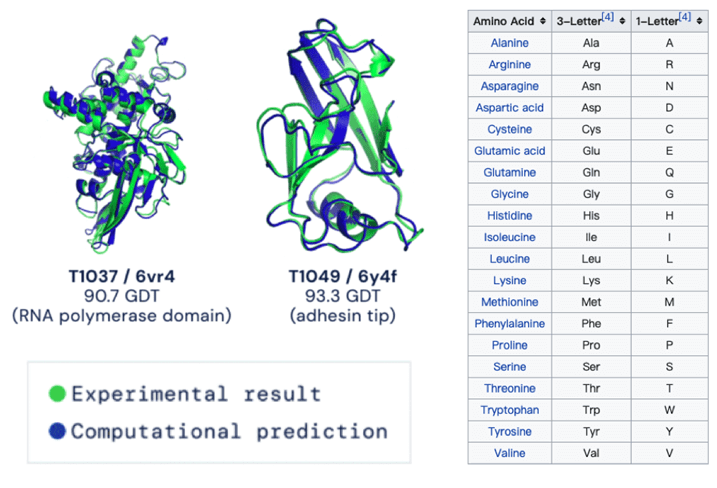
アミノ酸配列を文字列に置き換え、分析することで新型コロナウイルスを構成するたんぱく質の3D構造を予測することができます。
AlphaFold 2はこれを活用してタンパク質がどのような機能で、どのような役割を果たすのかなど様々な発見に役立てられています。
ハーバード大学の研究者たちは、これらと同じような技術を用いて新型コロナウイルスの突然異変を予測しています。
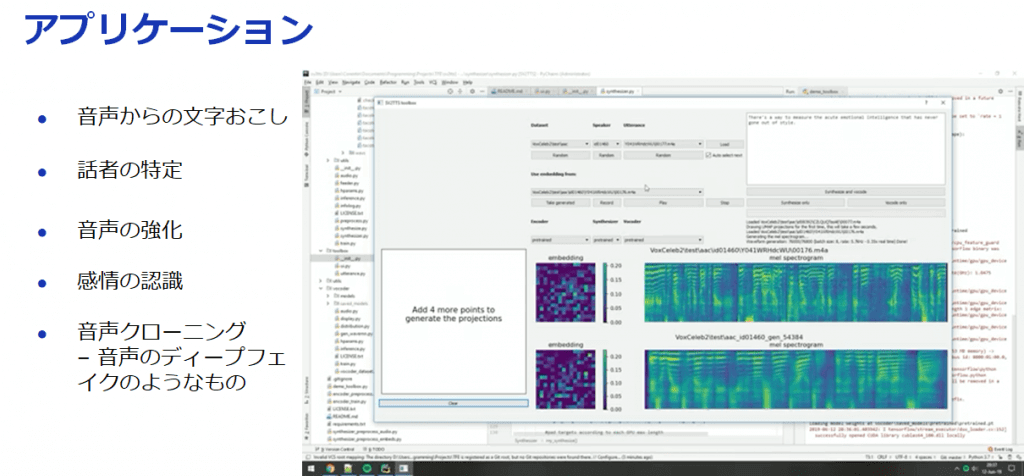
アメリカの国立研究所などが開発した「IMPECCABLE」は、新型コロナウイルス感染症候補薬を評価し、創薬の工法をスクリーニングするために使われています。
これはAIとコンピュータ処理ツール、そしX線結晶学の構造解析の組み合わせによる統合モデリングパイプラインです。
このようなスクリーニングプロセスが開発される前は、1日に処理できるスクリーニングの対象の数が数百万単位でした。
しかし、AIを活用することで完全なエンドツーエンドのスクリーニングのパイプラインが開発され、1日に処理できる数が数十億となりました。
これにより、従来の手法に比べて最高5万倍の速度で化合物を評価できるようになりました。
ミン・スン氏はこの成果を「研究のポイントはエンドツーエンドのパイプラインの中にAIを導入し、そして堅牢なパイプラインを作り上げたことだ」と説明しています。
ミン・スン氏は、シーケンシャル・データのモデリングはビジネスにおいて特に「テキスト」と「音声」の2つの分野で有用だと述べています。
昨年、1,000億を超えるパラメーターを扱える大規模言語モデルGPT-3が注目されましたが、今年に入り、その6倍以上の兆レベルのパラメーターに対応した「Switch Transformer」が登場しました。
ミン・スン氏は、学習コストや提供コストが抑制され、今後1~3年で言語の理解や生成能力が大きく進歩すると予測します。
音声データの文字起こしは、英語・中国語・日本語などのビジネスシーンで利用者が多い言語では成熟しつつあります。
一方長尺の音声においては、それ以外の言語への対応は十分とはいえず、5~10%のエラーが出てしまうのが現状です。
昨年、新型コロナウイルスによる巣ごもり需要で、長尺の音声コンテンツが人気となり、Clubhouseなどの会話型SNSがヒットし、日本での利用者が増えています。
増加している音声データをどう活用するかがビジネス上でのポイントになります。
GPT-3やSwitch Transformerなどで利用できる‶自己教師あり学習”を適用すると、入力用の音声ファイルからアノテーションなしで教師用データを抽出できます。
音声は生データのサンプリングから、音素に分解、音節を特定し、単語に結びつけていくという手間が加わります。
そのため、連続性を持った長尺の音声は、データポイントが膨大になる上、複雑な階層構造があるため、学習が難しいとされています。
ミン・スン氏はAI技術の進歩により、今後1~3年で長尺音声の文字起こしが可能になると予測します。
今後は、音声データを直接検索したり、ソーシャルチャネルでやり取りされる音声でトレンド分析することもできると言われています。
他人の声を使って成りすます音声クローンのような使い方が出てくる懸念はあるものの、リモート会議中の自分の音声を加工し、プロのアナウンサーのような美声にしたり、ものを食べている咀しゃく音をカットできる技術もまもなく利用可能になるとも予測されています。
今後の展開も、ますます目が離せなくなりそうです。
出典:PR TIMES
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。











.png)




FOLLOW US
SNSをフォローして、最新情報をチェックできます!






AI製品・ソリューションの掲載を
希望される企業様はこちら