
ChatGPT連携サービス


 ChatGPT連携サービス
ChatGPT連携サービス
 生成AI
生成AI
 AI受託開発
AI受託開発
 対話型AI -Conversational AI-
対話型AI -Conversational AI-
 ボイスボット
ボイスボット
 バーチャルヒューマン
バーチャルヒューマン
 教師データ作成
教師データ作成
 ナレッジマネジメントツール
ナレッジマネジメントツール
 AI研究開発
AI研究開発
 通訳・翻訳
通訳・翻訳
 AI・自動受付システム
AI・自動受付システム
 声紋認証
声紋認証
 機密情報共有・管理
機密情報共有・管理
 契約書管理システム
契約書管理システム
 ワークステーション
ワークステーション
 FAQシステム
FAQシステム
 AIカメラ
AIカメラ
 生体認証
生体認証

 電子帳簿保存法の電子保存対応ソフト
電子帳簿保存法の電子保存対応ソフト
 インボイス制度対応システム
インボイス制度対応システム
 データセットの収集・購入
データセットの収集・購入
 コールセンター
コールセンター
 人事・総務向け
人事・総務向け
 インバウンド対策
インバウンド対策
 コンバージョンアップ
コンバージョンアップ
 KYT・危険予知で労働災害防止
KYT・危険予知で労働災害防止
 無料AI活用
無料AI活用
 顧客リスト自動生成
顧客リスト自動生成
 ロボットで自動化
ロボットで自動化
 LINE連携
LINE連携
 セキュリティー強化
セキュリティー強化
 テレワーク導入
テレワーク導入
 AI学習データ作成
AI学習データ作成
 配送ルート最適化
配送ルート最適化
 非接触AI
非接触AI
 受付をAIで自動化、効率化
受付をAIで自動化、効率化
 AIリテラシーの向上サービス
AIリテラシーの向上サービス
 日本語の手書き文字対応AI-OCR
日本語の手書き文字対応AI-OCR
 Windows作業の自動化RPAツール
Windows作業の自動化RPAツール
 リスク分析AIで与信管理
リスク分析AIで与信管理
 紙帳票仕分けAI-OCRサービス
紙帳票仕分けAI-OCRサービス
 サプライチェーン
サプライチェーン
 自治体向けAI
AIコンサルティング
自治体向けAI
AIコンサルティング


最終更新日:2024/01/19
近年はさまざまな技術の発展により、より高度なサービスを提供する事例が多くなりました。それは、コミュニケーションを図る上で必要不可欠な「言語」という分野においてもいえることであり、機械翻訳や、かな漢字変換などの「自然言語処理」にも活用されているのです。
では、この「自然言語処理」とは一体どのようなものなのでしょうか。今回は、自然言語処理の仕組みについて詳しく解説していくとともに、活用事例や自然言語処理AIサービスなどもご紹介していきますので、ぜひ参考にしてみてください。
AIソリューションについて詳しく知りたい方は以下の記事もご覧ください。
AIソリューションの種類と事例を一覧に比較・紹介!

自然言語処理とは私たち人間が普段使う言葉(自然言語)をコンピュータが処理できるようにプログラミング言語に変換する処理です。
自然言語処理について詳しくご紹介する前に、まずは「そもそも自然言語とは何なのか」という点から詳しく掘り下げていきましょう。自然言語とは、私たち人間が日常的に話したり書いたりしている日本語や英語、フランス語といった「自然な言語」のことを指します。この自然言語の対照的な存在が、プログラミング言語です。
プログラミング言語には一切の曖昧性がありませんが、自然言語には曖昧性があるため、その言葉(文字)の意味を正しく理解することは決して簡単なことではありませんでした。
例えば、「黒い目の大きい金魚」という言葉があったとします。この場合、「“目が黒い”“大きな金魚”」というニュアンスにもなりますし、「“黒い色”の“目が大きな金魚”」というニュアンスにもなるわけです。そのため、本来伝えたい意味とは異なって伝わってしまうというケースも少なくありません。
その点、プログラミング言語の場合は、「5+3+1=9」といった計算式のように、答えがひとつしか存在しません。コンピューターの制御を行うためのプログラムを記述する言語なので、すべてのコンピューターが同じ解釈をすることができるわけです。だからこそ、プログラミングにおいて「コンピューターごとに異なる動きをしてしまう」という事態が引き起こることはありません。
自然言語種類は、「自然言語理解(NLU)」と「自然言語生成(NLG)」の2種類に分けることができます。それぞれにどのような特徴があるのでしょうか。詳しくみていきましょう。
自然言語理解(NLU)とは、自然言語処理の内の一分野であり、「テキストや音声の構文(文の文法的構造)、意味(文が意図する意味)解析を使用することで文の意味を判別していく技術」です。
そんなNLU は、関連するオントロジーも構築していくことが特徴として挙げられます。オントロジーとは、語と句の間の関係を指定するデータ構造のことです。人間は、日常会話においてごく自然にこのオントロジーを行っているわけですが、機械が人間と同じようにさまざまなテキストの意味を理解するためには、これらの分析を組み合わせなければなりません。
自然言語生成(NLG)も、自然言語処理の内の一分野です。コンピューターの読解力に焦点を置いた技術ですが、自然言語生成(NLG)はコンピューターが文章を生成できるようにしている点が大きな特徴といえます。
自然言語生成(NLG)は、あるデータ入力に基づき、人間の言語によってテキスト応答を生成していくプロセスを指します。ここでテキストが生成されたら、音声合成サービスを介して音声の形式に変換していくことも可能です。そんな自然言語生成(NLG) には、テキストの要約機能も含まれます。これは、情報の整合性を保ちながら入力された文書の要約を生成していくという仕組みとなり、AI の革新的技術として大きな注目を集めています。
自然言語生成(NLG)システムは、もともとテンプレートを使用する形でテキスト生成を行っていました。何らかのデータ・クエリーをもとに、言葉遊びゲームのような形で空白を埋めていたわけです。しかし、技術の発展に伴い、再帰型ニューラル・ネットワークやトランスフォーマーの適用が可能になり、リアルタイムでより動的なテキスト生成を行えるようになりました。

自然言語処理の歴史は、1940年代まで遡ります。1940〜1960年頃は黎明期と呼ばれており、1946年に初めてコンピュータが誕生しました。当初は、弾道計算や暗号解読といった軍事利用が主な目的だったといいます。しかし、ロックフェーラー財団のウィーバーが、このコンピュータが翻訳にも活用できるかもしれないと考えたことがきっかけとなり、米国内で機械翻訳への関心が高まっていきます。
そして1952年、ジョージタウン大学とIBMが共同で翻訳プロジェクトを始動し、ロシア語から英語に翻訳を行うという小規模な実験が行われました。これが、自然言語処理の始まりです。その後、アメリカはソ連の科学技術の実態をリサーチするために、「ロシア語→英語」の翻訳に関連する研究に、膨大な研究予算を投入しました。そうして、機械翻訳は一気に進展していったのです。
1960〜1990年頃は忍耐期と呼ばれており、莫大な研究費を費やすものの、研究が進展するごとに問題の難しさが認識されるような状況になったといいます。1967年には、Brown Corpusという米国の言語の仕様を調査する目的で、電子化された文書として初の100万語規模のコーパスが発表されました。コーパスとは、テキスト文書の集合に特定の情報を付与したもののことです。1970年代に入り、コンピュータの処理能力向上とともに言語やテキストを扱う環境も少しずつ整い始めましたが、機械翻訳のような知的処理に関しては、まだ実用化できるほどの精度が足りていない状況だったといいます。
そして1990年頃から現在までは「発展期」と呼ばれています。この間にインターネットが世界的に普及し始めたことを踏まえると、まさに社会基盤になった時期といえるでしょう。2000年代には、「マシンパワー増大」「ビックデータ活用」「アルゴリズム改良」といったトピックもあり、再び注目され始めるきっかけとなりました。
2010年代に入ると、画像認識や音声認識といったさまざまなタスクにおいて、大幅な精度の向上が見受けられるようになりました。特に、ニューラルネットワークを活用した翻訳手法である「ニューラル機械翻訳」は、大幅に精度が向上され、機械翻訳を実用化できるほどの技術にまで発展させました。

自然言語は、プログラミング言語とは異なり曖昧性が存在するわけですが、その曖昧性を克服し、適切な形でテキストデータを活用するために用いられるのが「自然言語処理」という技術です。そんな自然言語処理を行うためには、「機械可読辞書」と「コーパス」の2つが欠かせません。
機械可読辞書とは、「コンピューターが単語の総体である語彙(ごい)を理解するために必要となる辞書」のことです。書き言葉の書籍情報や関連情報などを機械が正しく読み込むことができるように置き換えた通信規格であり、いわば「ロボットの目」のような役割を担っています。
この機械可読辞書は、1960年に開発されました。応用技術のひとつとして、図書館などで使用されている書籍検索システム「OPAC」が挙げられます。実際に使用したことがある方も多いのではないでしょうか。
機械可読辞書は自然言語処理用の「辞書」と定義されており、ここで機械が文字を読み取れる規格への変換を行います。一見、私たち人間が日常的に使用している辞書と同じもののように感じられるかもしれませんが、その辞書とは大きく異なります。
コーパスとは、自然言語処理を行う際に必要となる「自然言語の文章を構造化して大規模に集積したもの」を指します。このコーパスの分析を行うことで、状況に適した言葉の意味、使い方を理解することができるようになるわけです。最近では、コンピューター自体の処理性能や記憶容量も高まってきている状況にあるため、より大規模なコーパスを利用して言語処理を行うことができるようになっています。
特に近年では多くのスマホユーザーがSNSによる情報発信を行っている状況にあり、日々大量の言葉を用いたやりとりが行われている状況です。そのため、こういったSNSのデータを収集していくことで、より一層大規模なコーパスを作成することができるようになるかもしれません。
機械可読辞書とコーパスの用意が完了すると、次に行われるのが形態素解析という作業です。「形態素」は言語学の用語であり、意味を持つ表現要素の最小単位のことです。これだけでは意味が分からない方も多いかと思いますので、先ほどの「黒い目の大きい金魚」という言葉を用いて解説していきます。
この「黒い目の大きい金魚」というフレーズは、「黒い」「目」「の」「大きい」「金魚」という形態素で分割することができるわけです。このように分割していく作業を「形態素解析」と呼びます。形態素解析を行うことで意味のある情報の取得ができるようになり、それぞれの形態素に「形容詞」「名詞」「助詞」といった品詞を適切に割り当てていくことが可能になるのです。ただ、どれくらい詳細な品詞を割り当てるかどうかは形態素解析を行うツールの精度によって異なるため、一概に測ることはできません。
構文解析とは、「一つひとつの形態素データがどの形態素データと隣り合わせになっているのか」を確認していく工程のことです。日本語の構文解析では、形態素解析によって分割された単語同士の関連性を解析した上で、「分節感の係り受け構造を見つけてツリー化(図式化)していくこと」が主な目的となっています。そんな構文解析には、以下2つの解析手法が存在します。
依存構造とは、単語や文節間における「修飾・被修飾関係」「係り受け関係」などの依存関係をもとに、文章の構造を表したものです。単語・文節を接点とするツリーによって表現されます。
つまり依存構造解析は、文章内における「単語間の係り受け関係」を調べた上で、「どの単語がどの単語に係るのか」を構文的に解析していく作業というわけです。日本語の構文的依存構造関係について出力していく構文解析器(parser)としては、CaboChaやKNPなどが挙げられます。
意味解析とは、構文解析された文章内の意味を解釈していく工程のことです。日本語の場合、ひとつの原文に対して複数の解釈ができるケースも少なくありません。その一例として、以下のような文章が挙げられるでしょう。
「私は冷たいビールとメロンが好きだ。」
この文章の場合、「私は|冷たい|ビールとメロン|が好きだ。」という解釈であればどちらも「冷たい」と認識できます。しかし、「私は|冷たいビール|と|メロン|が好きだ。」という解釈であれば、メロンの冷たさは問わないことになるわけです。
このように、複数の解釈ができる文章において、正しい解釈を選択するために必要となるのが意味解析です。意味解析においては、「意味」という概念を持たない機械に対して自然言語文の意味を適切に伝え、理解させなければなりません。
しかし、日本語においては、一つの単語に複数の意味がある場合も多いため、他の単語とのつながりを踏まえた上で、適切な候補を選び出す必要があります。その候補を絞り込む作業は、非常に難易度が高い処理なのです。
文脈解析とは、文章の繋がり(文脈)を考えていく工程のことです。複数の文に対して「文同士のつながり」を解析するためには、文章の背景など複雑な情報も必要になります。
そのため、意味解析よりもさらに難易度は高く、現状では実用分野への応用が難しいといわれています。
自然言語処理を詳しく理解する上では、word2vecとdoc2vecという2つの技術も重要になります。それぞれどのような特徴を持った技術なのか、詳しくみていきましょう。
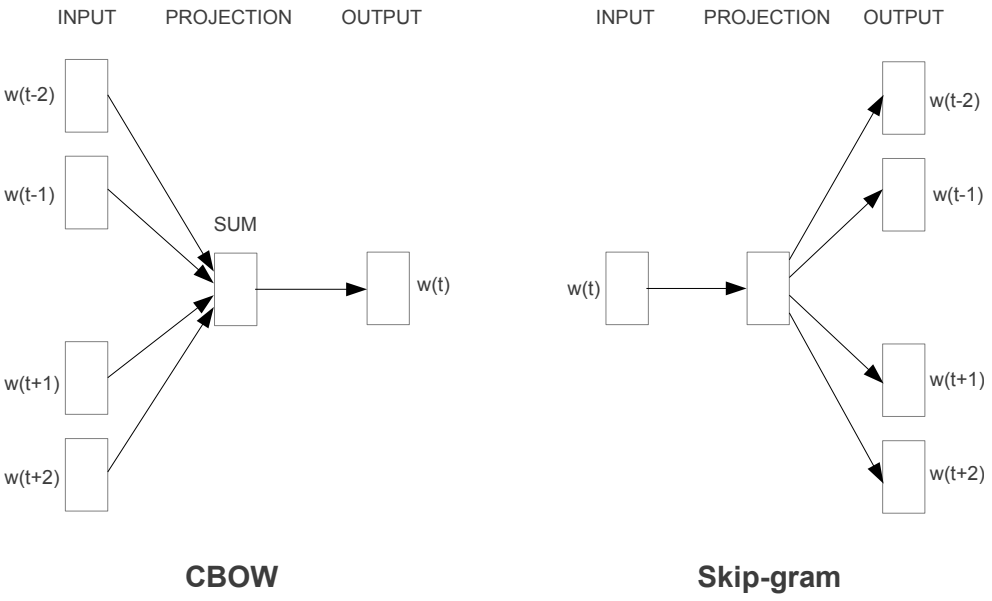 参考:”Efficient Estimation of Word Representations in Vector Space” Tomas Mikolov [2013]
参考:”Efficient Estimation of Word Representations in Vector Space” Tomas Mikolov [2013]
word2vecとは、テキスト処理を行うためのニューラルネットワークのことです。膨大な量のテキストデータを解析し、単語の意味をベクトル化することによって、単語の意味の類似性を見つけたり、単語同士の意味を足し引きしたりすることが可能になります。このword2vecは、TensorFlowなどのソフトウェアライブラリで手軽に試すことができるのも大きな特徴のひとつです。
そんなword2veの仕組みを簡単にご紹介すると、例えば「ぶどう、パイナップル、果物、交ジュース」という単語をベクトル化し、以下のような数値になったとします。
ぶどう:8
パイナップル:6
果物:7
ジュース:3
これは、ベクトル化によって「ぶどう」に最も近いのが「果物」であり、「パイナップル」にもそれなりの類似性があることが示されているわけです。ちなみに、Word2Vecは、大きく分けて2種類の論理的構造(アーキテクチャ)が存在しています。単語周辺の文脈から、その中心となる単語を推測していくCBOW。中心となる単語から、文脈の構成に重要となる要素を推測していくSkip-gramです。
doc2vecとは、任意の長さの文書をベクトル化する技術のことです。文章やテキストに対して、分散表現(Document Embeddings)を獲得することができる。そんなdoc2vecは、特定のタスクに依存されることがありません。そのため、以下の例をはじめとする多くの応用方法が存在します。
また、機械学習のモデルにおける入力には、固定長のベクトルが使用されるケースが多いため、事前にDoc2Vecで前処理を行なった上で、入力ベクトルにするケースも少なくありません。これまでにもBag-of-wordsやLDAなど、文書を固定長の小さなベクトルにするテクニックは存在していましたが、Doc2Vecを利用することで、それらのテクニックを上回る性能を発揮することが報告されているのです。
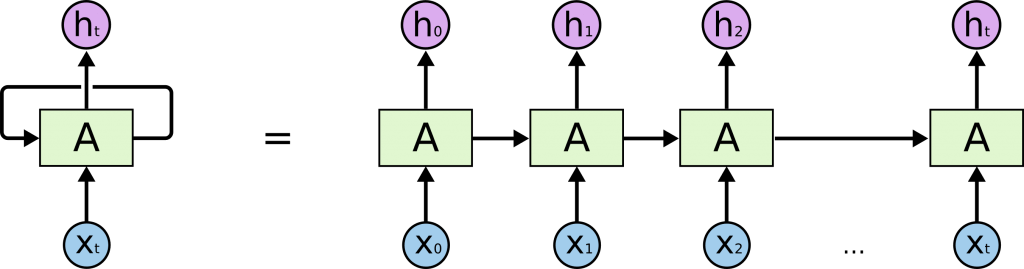 参考:Understanding LSTM Networks
参考:Understanding LSTM Networks
RNNとは、簡単に説明すると「過去のデータを使用できる」という特徴を持ったディープラーニングのことです。2016年11月頃、Googleが提供する翻訳機能が飛躍的に向上したことで一躍注目を浴び、Google翻訳の名も有名になりました。これは、Google翻訳にRNNが組み込まれたことが要因といっても過言ではないでしょう。
このようなRNNですが、動画や文章といった長い時系列データの場合、ネットワークが時系列長と比べて非常に深くなってしまうのも特徴のひとつです。そのため、情報が上手く伝達されないことも少なくありません。
そのような中で、ある程度の長い時系列データであっても学習できるように考案されたのが、次のLSTMと呼ばれるモデルです。
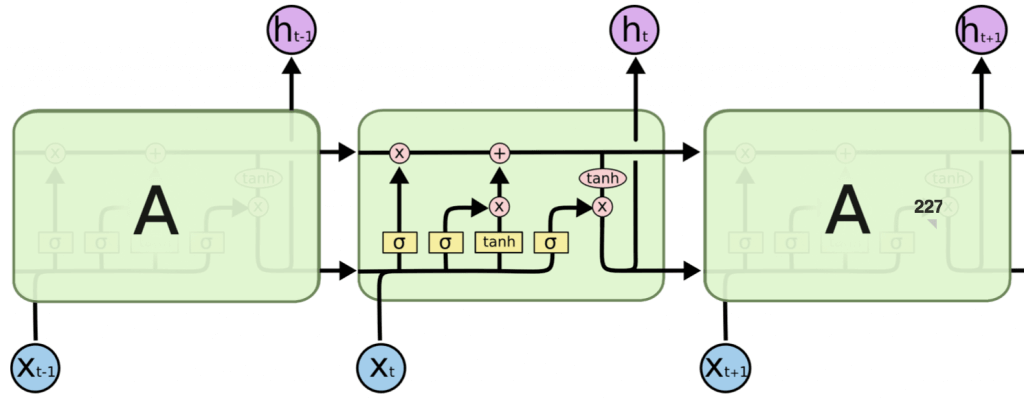 参考:Understanding LSTM Networks
参考:Understanding LSTM Networks
LSTMは、ある程度の長い時系列データでも学習ができるように考案されたモデルであり、「中間層にあるユニットをメモリユニットという要素で置き換えていること」が大きな特徴です。特別な種類のリカレントニューラルネットワークであるため、さまざまなタスクにおいて標準バージョン以上に優れた働きをしてくれます。
LSTMは、長期の依存性という問題を回避できるよう設計されています。「長時間の情報の記憶」に関しては実質的にデフォルトの動作なので、学習に苦労することもありません。
トランスフォーマー(Transformer)とは、自然言語処理タスクにおける強力なネットワークです。2017年に登場した比較的新しいネットワークであり、より素早く情報を集約できる自己注意機構(Self-Attention)を備えていることから注目されています。
これまで、高精度かつ学習時間も短い従来のモデルにおいては、RNNやCNNなど用いるのが一般的でした。しかし、トランスフォーマー(Transformer)ではAttentionという機構だけでネットワークを構築しているのが大きな特徴といえます。Attentionとは、簡単にいえば「文に含まれる単語の意味を理解する上で、どの単語に注目すれば良いのかを示すスコア」です。
入力されたデータに対してスコアリングを行い、重要性を考慮したベクトル量として出力していきます。例えば、ある画像データが入力されて画像の説明を出力するとしましょう。この場合、Attention機構は生成済みの単語のコンテクスト情報を前の隠れ層から受け取って「次の画像の注目ポイント」を推論していくわけです。
BERTとは、Bidirectional Encoder Representations from Transformersを略した自然言語処理モデルであり、2018年10月にGoogle社のJacob Devlin氏らが発表したことで、大きな注目を集めました。日本語では「Transformerによる双方向のエンコード表現」と訳されています。
一般的に、翻訳や文書分類、質問応答といった自然言語処理における仕事の分野を「(自然言語処理)タスク」と呼びます。BERTは、この「タスク」において2018年当時の最高スコアを叩き出したことで注目されたわけです。
BERTの特徴として、「文脈を読めるようになったこと」が挙げられます。Transformerと呼ばれるアーキテクチャ(構造)を組み込むことによって、文章を文頭・文末の双方向から学習し、文脈を読めるようになったのです。
GPT-3とは、イーロン・マスクをはじめとする有力な実業家や投資家が、2015年12月に参加したことで大きな注目を集めた言語モデルです。開発はOpenAIが行っています。約45TBという大規模なテキストデータのコーパスを、約1,750億個のパラメータを用いて学習していくという仕組みになっています。そのため、ある単語の次に用いられる単語の予測を高精度で行うことができるのです。
こういった技術で、あたかも人間が書いたような文章を生成できることから、さまざまな場所で活用され始めています。
PaLMは、2022年4月にGoogleが発表した言語モデルです。GPT-3では1,750億パラメータであったのに対し、PaLM は5,400億パラメータを持っており、非常に大規模なモデルであることがお分かりいただけるでしょう。このパラメータ数が大きくなればなるほど、賢くなっているといえます。
では、実際に自然言語処理はどのような場所で活用されているのでしょうか。ここからは、自然言語処理の活用事例やできることを詳しくみていきましょう。
代表的な活用事例として挙げられるのが、対話型AIです。対話型AIには、大きく分けて「チャットボット」と「ボイスボット」の2種類が存在します。
チャットボットとは、「チャット(会話)」と「ロボット」を組み合わせた言葉で、ユーザーの問いかけに合わせて返事をしてくれるプログラムです。
自然言語処理を用いたAIチャットボットの代表的な導入事例としては、パナソニック株式会社 グローバル調達社が挙げられます。パナソニック株式会社 グローバル調達社では、下請法や接待に関する社内ヘルプデスク業務をAIチャットボット FAQ で自動化し、効率化につなげることに成功しました。2018年4月に「WisTalk(ウィズトーク)」をもとに構築した「守くん」をリリースし、ヘルプデスク業務の効率化を図っています。
社内ヘルプデスク業務の多くは、コンプライアンスに大きく関わってくる内容であるため、回答に正確性が求められるのはもちろんのこと、ユーザーが回答を読んですぐ理解できるという点を重視する必要があったといいます。そのため、簡単で親しみやすい文章にすることに留意したそうです。
現在は1日10件以上、月換算だと200件以上の質問が「守くん」に寄せられているといいます。また、質問者からの評価や利用の多い項目の検証などを行うことで、ユーザーが気軽に使え、かつ疑問がすぐに解消できるツールとしての浸透を図っているそうです。導入初年度は5回、2年目となる2019年度には2回のアップデートを行うことで、「守くん」で解決できる質問の幅を広げています。
ボイスボットとは、AI(人工知能)が搭載されている音声認識のソフトウェアを用いて、ユーザーが音声によってシステムを操作する仕組みのことです。ボイスボットを利用すれば、一般的なIVR(自動応答ツール)のように、受話器から流れてくるガイダンスを聞きながら番号ボタンを押す必要がありません。
また、Amazonのスマートスピーカー「Alexa」などで知られる対話システムもボイスボットの一種であり、自然言語処理によって実現されています。こういったスマートスピーカーを利用したことがある方であれば、人との会話に近づいてきていることがお分かりいただけるのではないでしょうか。
そんなスマートスピーカーには、さまざまなことを指示することができます。例えば、指示されたアプリを立ち上げるという作業です。人が「Alexa、○○を開いて」と指示を出せば、スマートスピーカーはその自然言語を的確に解釈し、その指示通りの操作を実行していきます。
テキストマイニングとは、テキストデータを活用したデータマイニング技術のことです。データマイニングとは、膨大なデータをAIや統計学によって処理・分析することで、自社にとって有用な情報を抽出する技術を指します。
テキストマイニングをはじめとするビッグデータの活用サービスは、さまざまな企業で導入されています。そのひとつの事例として、BigData Proccessing AI System「SOFIT Super REALISM」を活用している製造会社が挙げられるでしょう。この企業では、工場の IoT 化の一環として、製造ラインの見える化に取り組んでいます。
センサや設備など異なるデバイスから収集したデータは、形式や定義が不ぞろいなため統合できず、また、製造ラインのトレーサビリティの処理に1日以上かかることも分かり、ビッグデータの処理速度にも課題があったといいます。また、経営層からは、ラインだけでなく工場全体や海外拠点との連携を見据えた見える化を求められていたそうです。
そこで「SOFIT Super REALISM」を導入したところ、これまで以上にデータの確認や整備が簡単に行えるようになり、効率良く統合できるようになったといいます。また、処理を「SOFIT Super REALISM」に置き換えることで、特定時間が90%以上短縮され、報告も即日行えるようになったそうです。
テキストをある言語から別の言語に自動で翻訳していく「機械翻訳」でも、自然言語処理が用いられています。そんな機械翻訳における自然言語処理の活用事例としては、Wovn Technologiesが挙げられるでしょう。
Web サイト多言語化ソリューション『WOVN.io(ウォーブン・ドットアイオー)』、アプリ多言語化ソリューション『WOVN.app(ウォーブン・ドットアップ)』を提供する Wovn Technologiesでは、ニューラル機械翻訳サービス『DeepL』との連携を開始したことで大きな注目を集めています。
WOVN.io は、Web サイトを最大43言語・77のロケール(言語と地域の組み合わせ)に多言語化し、海外戦略・在留外国人対応を成功に導く多言語化ソリューションです。既存の Web サイトに後付けすることができ、多言語化に必要なシステム開発・多言語サイト運用にかかる、不要なコストの圧縮・人的リソースの削減・導入期間の短縮が実現できます。
これまでも『Google 翻訳』、『みらい翻訳』、Microsoft Azure Cognitive Services の『Translator』といった様々な AI 翻訳エンジンと連携しており、今回新たに翻訳精度の高さと翻訳文の自然さ・流暢さに強みを持つ『DeepL』との接続が可能となりました。
DeepL は、ブラインドテストで世界最高レベルであることが示された機械翻訳システムです。独自のニューラルネットワークを数学的・方法論的に改善することで、一際高い品質を誇る機械翻訳の提供を実現。「直訳的でない、あくまでも自然な文脈での翻訳」を可能にし、多くのビジネスシーンで活用されています。
エンタープライズサーチ(Enterprise Search)とは、企業が保有し社内外に保管しているデジタルデータを、保管場所を意識せずに一括で横断検索するものです。AI検索システムと呼ばれることもあり、ここでも自然言語処理は活用されています。
多くの企業は、蓄積されたデータを厳重に管理し、資産として大事に活用していくわけですが、その蓄積されたデータを有効に活用できないまま眠らせてしまっているケースも少なくありません。そのようなときに、必要な情報を素早く見つけ出すことができるのが、エンタープライズサーチなのです。
AI技術(自然言語処理、機械学習など)を活用することで、自然文で入力された文章がドキュメントとは完全に一致していなくても、目的のドキュメントを検索することができるようになります。そのため、「あいまいなイメージ」だけしか持てていない場合でも、目的のデータを探し当てられる可能性が高まるというわけです。
そんなAI検索システムの導入事例としては、「Click Navi」を活用している住友電工情報システム株式会社が挙げられるでしょう。Click Naviは、『AIで「探し方」改革! クリックだけで情報探し!』をコンセプトに、文字入力不要でクリックだけで目的の文書にたどり着ける新しい「探し方」を提案するシステムです。基本操作はクリックだけなので、パソコン操作が不慣れな方や、外出先のスマートデバイスでも簡単に利用できるのが特徴です。
また、頻繁に利用する検索条件をカテゴリとして設定(AIで候補を自動提示)しておくことで、文字入力せずに、カテゴリをクリックするだけで文書を探すことができます。検索の起点は、「カテゴリ」だけでなく「検索対象の種類」「更新日」などに切り替えることも可能です。
文章要約やテキスト分類においても、自然言語処理が活用されています。テキスト分類とは、その文章がどんな内容について書かれているものなのかを調べ、トピックごとに分類していく作業のことを指します。これまでは、人間が実際に目を通すことで実現されてきた作業ですが、近年はこの作業をAIによって自動化、高精度化させることが可能になってきているのです。
テキスト分類は、特定のキーワードをもとにカテゴライズしていくことが可能なため、最近ではさまざまな業務でも活用され始めています。たとえば、ホテルの予約フォームの備考欄に「追加ベッド関係」のテキストが含まれていれば、その旨を客室係のスタッフに通知させる仕組みを構築することができるわけです。これにより、客室係はスムーズに必要な情報をキャッチできるようになり、さらなる業務効率化を図れるようになります。
また、予約フォームの備考欄に「アレルギー関係の記載」があれば、その情報がレストランに自動共有されるように仕組みを構築することも可能です。これらは、機械学習・AIを活用したテキスト分類という技術があるからこそ実現できるものといえるでしょう。
画像生成やテキスト生成でも、自然言語処理が活用されています。たとえば画像生成では、絵画の生成や画像・映像などの自動加工を行うことが可能です。
近年は、さまざまな場面において高品質な画像が要求されるようになりました。しかし、常にその要求に応えられる完全なオリジナル画像を取得できるわけではありません。たとえば、ピントの合っていないぼやけた画像データしか用意できないケースも考えられます。また、歴史的資料であれば、カラー写真が存在せず、白黒写真しか用意できないケースも多く、ラフスケッチしか存在していないケースなども考えられます。
このような場合、専門的で工数のかかる画像加工を行ったり、イラストを描きながら撮影コンセプトを固めて写真を撮影したりしながら、高品質な画像データを準備するのは難しいのが実情です。ただ、近年はAIの技術が発展したことにより、不十分なデータからでも高品質な画像を作り出すことができるようになってきたのです。
AI技術の発展による恩恵は、テキスト生成の分野でも生じています。その代表例ともいえるのが、AIが小説を代筆する文章・小説作成アプリケーションソフトウェア「AIのべりすと」です。文庫本に換算すれば174万冊分の知識が蓄積されたAIを搭載しており、利用者が簡単にAIの力を借りて小説を書けることから大きな注目を集めています。

今回は、自然言語処理の仕組みや歴史、そして活用事例などについて詳しくご紹介しました。自然言語処理は、音声認識や文字認識、検索システム、そしてビッグデータ活用など、さまざまな領域で活用されている技術であることがお分かりいただけたのではないでしょうか。高い精度での分析を行う上で、非常に重要な役割を果たしているのです。
最近では、複数の異なる情報を用いた機械学習の「マルチモーダル」にも大きな注目が集まり始めています。このマルチモーダル学習が発展することで、機械翻訳はさらに進化を遂げていくかもしれません。
ただし、著作権等侵害等の法律に関しては、まだ完全に整備されているわけではなく、今後の課題も多く残っているのが現状です。これからどのような形でAI(人工知能)の分野が進歩していくのか、注目していきましょう。
AIsmileyではG検定を取得したコンサルタントによる無料相談を承っております。社内の蓄積したアンケートの分析や過去の技術文書へのアクセスを容易にするなどAIを活用してみませんか?他社の動向や事例集のプレゼントもありますのでお気軽にお問い合わせください。
AIについて詳しく知りたい方は以下の記事もご覧ください。
AI・人工知能とは?定義・歴史・種類・仕組みから事例まで徹底解説
業務の課題解決に繋がる最新DX・情報をお届けいたします。
メールマガジンの配信をご希望の方は、下記フォームよりご登録ください。登録無料です。








.png)




FOLLOW US
SNSをフォローして、最新情報をチェックできます!








AI製品・ソリューションの掲載を
希望される企業様はこちら